Googleが提供する大規模言語モデル(LLM)「Gemini」に、新たにファインチューニング機能が追加されました。この機能により、ユーザーは特定のタスクやユースケースに合わせてモデルの性能を最適化できるようになります。企業や開発者にとって、AIソリューションの柔軟性と効率性が大幅に向上する革新的な機能です。
このニュースのポイント
- Google Geminiがファインチューニング機能を新たに搭載
- 特定タスクに最適化されたAIモデル構築が可能に
- Gemini APIを活用した効率的なデータセット準備と設定方法を解説
- 企業のAI導入における柔軟性と効果を大幅向上
ファインチューニングとは?
ファインチューニングは、既存のAIモデルを特定のタスクやユースケースに適合させるためのプロセスです。この技術により、事前学習済みのモデルに対し、独自のデータセットを使って新たな知識やスキルを学習させることができます。特に、Geminiではファインチューニングを通じて次のような効果が期待されています。
- タスク固有のパフォーマンス向上
- 出力内容のカスタマイズ
- モデルの効率的な再利用
運営コメント: 「ファインチューニング機能の導入で、これまで対応が難しかったニッチなタスクにもAIを活用できる可能性が広がりますね。」
データセットの準備と形式
効果的なファインチューニングを実現するには、高品質なデータセットの準備が不可欠です。Geminiでは以下の点が推奨されています。
- データセットの品質: 高品質で多様なデータ例を用意
- 形式の統一: 実際の運用データと整合性のあるデータフォーマット
- サンプル数: 100~500のサンプルを目安に準備
データ例の一部は以下のように構造化されます。
jsonコードをコピーする{
"text_input": "質問の内容",
"output": "期待される答え"
}
トレーニング データサイズ
20 個のサンプルでモデルをファインチューニングできます。追加データ 一般的に回答の質が向上します。アプリケーションに応じて、100~500 個のサンプルをターゲットにする必要があります。
次の表に、さまざまな一般的なタスクのテキストモデルをファインチューニングするための推奨データセットサイズを示します。
| タスク | データセットのサンプル数 |
|---|---|
| 分類 | 100 以上 |
| 要約 | 100 ~ 500 以上 |
| ドキュメントの検索 | 100 以上 |
高度な設定とモデルの最適化
ファインチューニングのプロセスでは、エポック数、学習率、バッチサイズなどのパラメータを調整可能です。これにより、モデルの性能をさらに引き出すことができます。
| パラメータ | 推奨設定 | 調整のポイント |
|---|---|---|
| エポック数 | 5 | 損失曲線が横ばいになるタイミングを目安に調整 |
| 学習率 | 0.001 | 小規模データセットではさらに低く設定 |
| バッチサイズ | 4 | メモリと計算資源に応じて調整 |
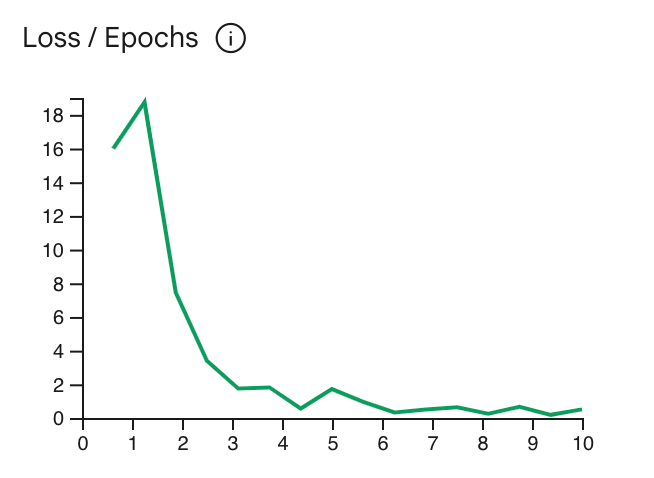
チューニングプロセスの簡素化
Gemini APIでは、ファインチューニング用データセットのアップロードやチューニングジョブの設定が簡単に行えます。Google AI Studioを活用することで、視覚的に進捗を確認でき、効率的な運用が可能です。
まとめ
Google Geminiのファインチューニング機能は、特定のユースケースに最適化されたAIモデルの構築を実現し、企業や開発者のAI導入を大きく前進させます。効率的なデータセットの準備や高度な設定を駆使して、Geminiを最大限に活用しましょう。