RAG(検索拡張生成)とは?わかりやすく解説!仕組み・メリット・活用事例まとめ

AIシステムの進化により、社内の膨大なデータを活用した高精度な情報提供が求められています。RAG(Retrieval Augmented Generation)は、既存のデータベースから関連情報を検索し、AIが自然な文章を生成する革新的な技術です。
本記事では、RAGの基本的な仕組みから実装方法、具体的な活用事例まで、実務で即活用できる知識を体系的に解説します。技術的な理解を深め、自社に最適なRAGシステムの構築方法を習得していただけます。
RAGとは?基本構成要素から動作原理までわかりやすく解説!
RAGは、AI言語モデルに最新の外部情報を柔軟に活用させる画期的な手法です。検索(Retrieval)と生成(Generation)を組み合わせ、ベクトルデータベースを活用して高精度な回答を実現します。
このセクションでは、RAGが登場した背景から基本構造、3つの重要コンポーネント、そしてデータ前処理の重要性まで、その仕組みと動作原理を体系的に解説していきます。
RAGの登場背景と従来のAIシステムとの違い
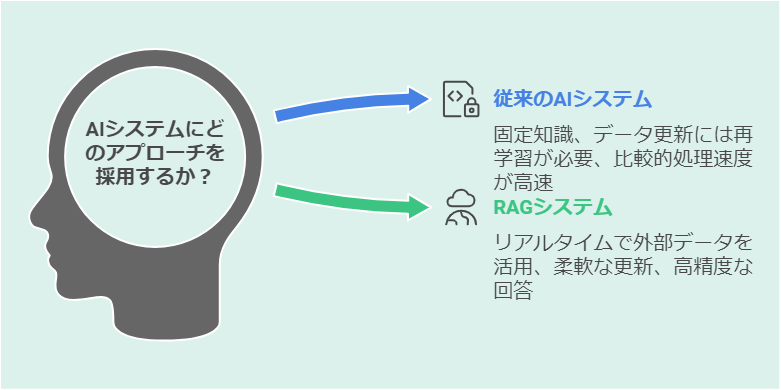
従来の大規模言語モデル(LLM)は、学習時点のデータに基づく固定的な知識しか持ち合わせていませんでした。このため、最新情報への対応や専門的な知識の更新に大きな課題を抱えていました。
RAGは、この課題を解決するために登場した革新的なアプローチです。従来型のAIシステムと比較した際の主な違いは以下の通りです。
| 従来型AI | ・事前学習済みの固定知識のみを使用 ・データ更新には再学習が必要 ・処理速度は比較的高速 |
|---|---|
| RAGシステム | ・外部情報をリアルタイムで活用 ・柔軟なデータ更新が可能 ・検索と生成を組み合わせた高精度な回答 |
RAGシステムの最大の特徴は、必要な情報を外部ソースから動的に取得し、それを基に回答を生成できる点です。これにより、常に最新の情報に基づいた正確な応答が可能になりました。
また、専門分野のデータを追加するだけで、特定領域の知識を簡単に拡張できる柔軟性も備えています。従来型AIでは困難だった迅速な知識更新が、RAGによって実現可能になったのです。
検索と生成を組み合わせたRAGの基本的な仕組み
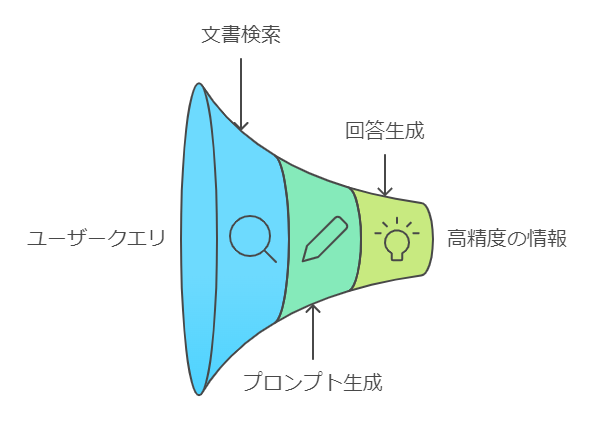
RAGの基本的な仕組みは、「検索(Retrieval)」と「生成(Generation)」の2つのプロセスが連携して動作する点に特徴があります。この2つのプロセスが効果的に組み合わさることで、高精度な情報提供を実現しています。
RAGの動作プロセスは以下の3つのステップで構成されています。
- ユーザーからの質問(クエリ)をベクトル化し、類似度の高い関連文書を検索
- 検索された文書とクエリを組み合わせて、LLMへのプロンプトを生成
- LLMが関連文書の情報を参照しながら、適切な回答を生成
このプロセスの中核となるのが、ベクトルデータベースを活用した効率的な類似度検索です。データはあらかじめベクトル化され、データベースに格納されています。質問が入力されると、システムは質問内容を同様にベクトル化し、最も関連性の高い情報を即座に特定します。
検索結果の品質はRAGの精度に直接影響するため、適切なインデックス作成と類似度計算アルゴリズムの選択が重要になります。また、検索された情報をLLMが適切に参照できるよう、プロンプトエンジニアリングも精度向上の鍵となっています。
RAGを構成する3つの重要技術コンポーネント
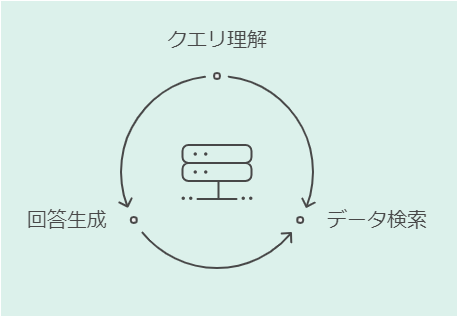
RAGシステムは3つの重要な技術コンポーネントから構成されており、それぞれが連携して高精度な情報検索と回答生成を実現します。
主要コンポーネントと役割
| コンポーネント | 主な機能 | 特徴 |
|---|---|---|
| リトリバー | クエリ理解と検索キーワード抽出 | 文脈を考慮した意味解析が可能 |
| ベクトルストア | 検索結果の保存と管理 | 高速な類似度検索を実現 |
| ジェネレーター | 最適な回答の生成 | 文脈に応じた自然な文章生成 |
リトリバーは、ユーザーからの質問を深く理解し、関連性の高い情報を効率的に検索するためのキーワードを抽出します。
ベクトルストアは、大量の文書やデータをベクトル形式で保存し、高速な類似度検索を可能にします。これにより、質問に最も関連性の高い情報を瞬時に特定できます。
ジェネレーターは、検索結果とユーザーの質問を組み合わせて、的確で自然な回答を生成します。文脈を理解し、必要に応じて複数の情報源を統合することで、より正確な回答を提供します。
データの前処理と構造化がRAGの性能を決める
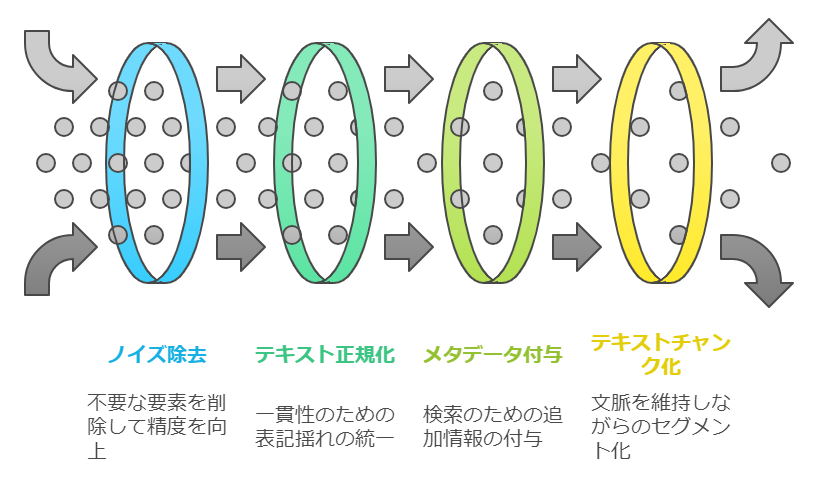
RAGにおけるデータの品質は、その性能を大きく左右する重要な要素です。効果的な検索と生成を実現するには、入力データに対する適切な前処理と構造化が不可欠となります。
| 前処理の種類 | 目的と効果 |
|---|---|
| ノイズ除去 | 不要な記号や空白の削除による検索精度の向上 |
| テキスト正規化 | 表記揺れの統一による検索漏れの防止 |
| メタデータ付与 | 効率的な検索とフィルタリングの実現 |
テキストの分割方法も重要な検討事項です。チャンクサイズが大きすぎると検索精度が低下し、小さすぎると文脈が失われてしまいます。一般的には500〜1000トークン程度を目安に、内容に応じて適切なサイズを設定します。
さらに、データの構造化においては、日付や著者、カテゴリーなどのメタデータを体系的に付与することで、検索時の絞り込みや優先順位付けが容易になります。これにより、より関連性の高い情報を効率的に抽出できるようになるのです。
RAGシステムの要となるリトリーバーとジェネレーターの仕組み
RAGシステムの核となるリトリーバーとジェネレーターは、それぞれが重要な役割を担っています。リトリーバーは入力内容から関連性の高い情報を正確に検索し、ジェネレーターはその結果を活用して自然な文章を生成します。
これらのコンポーネントはLLMと緊密に連携し、プロンプトの最適化を通じて高品質な応答を実現しています。このセクションでは、各要素の仕組みと効果的な活用方法を詳しく解説します。
高精度な情報検索を実現するリトリーバーの働き
リトリーバーは、ユーザーの入力から意図を適切に理解し、膨大なデータの中から関連性の高い情報を抽出する重要な役割を担っています。自然言語で入力されたクエリは、まずベクトル化されて検索に適した形式に変換されます。
このベクトル変換により、意味的な類似性を数値として扱えるようになります。変換されたクエリは、データベース内の情報とベクトル空間上で照合され、コサイン類似度などの指標によって関連度が計算されます。
| 評価指標 | 主な用途 |
|---|---|
| コサイン類似度 | ベクトル間の角度による類似性計算 |
| ユークリッド距離 | ベクトル間の直線距離による類似性計算 |
| BM25スコア | キーワードの重要度を考慮した関連性評価 |
検索結果は、これらの評価指標に基づいてランキング付けされ、より関連性の高い情報から順に選別されます。また、閾値の設定や重み付けの調整により、検索精度の最適化が可能です。
自然な文章生成を担うジェネレーターの特徴
ジェネレーターは、リトリーバーが収集した情報とユーザーのプロンプトを組み合わせ、自然な文章を生成する重要な役割を果たします。その際、事前に設計されたテンプレートに従って、文脈に沿った適切な応答を構築していきます。
文章生成の基本プロセス
文章生成は、検索結果の解析から始まり、プロンプトとの整合性確認を経て、最終的な応答の組み立てへと進みます。以下が主要なステップです。
- 検索結果の重要度分析と優先順位付け
- プロンプトの意図理解と文脈の把握
- 情報の統合と一貫性のある文章構築
- 生成文章の品質チェックと最適化
品質管理の仕組み
生成された文章の品質を確保するため、ジェネレーターは独自の品質管理メカニズムを備えています。文法的な正確性、情報の一貫性、ソース情報との整合性などを複数の観点から検証し、必要に応じて修正を加えます。
このように、ジェネレーターはLLMの推論能力を最大限に活用しながら、高品質な応答生成を実現しているのです。
大規模言語モデルとRAGの効果的な連携方法

RAGシステムでLLMの性能を最大限に引き出すには、適切なプロンプト設計が不可欠です。検索結果の品質に応じて動的にプロンプトを調整することで、より正確で信頼性の高い回答を生成できます。
効果的なプロンプト設計のポイント
- 検索結果の関連性を明示的に指示し、重要な情報に重点を置くよう指定
- 情報の新しさや信頼性に基づいて、検索結果の重み付けを調整
- LLMの持つ基礎知識と検索結果を適切にブレンドするための文脈提供
- 回答の根拠となる情報源を明確に示すよう指示
また、LLMの推論能力を活かすため、検索結果が不十分な場合は一般的な知識ベースでの補完を行い、十分な場合は検索結果を優先するというハイブリッドアプローチが効果的です。このバランスを適切に保つことで、最新性と正確性を両立した応答が可能になります。
プロンプト設計で実現する性能の最適化
RAGシステムの性能を最大限に引き出すには、プロンプトテンプレートの適切な設計が不可欠です。特に検索結果の組み込み方は、LLMの応答品質に大きな影響を与えます。
プロンプトの設計では、検索結果の重要度に応じた情報配置が重要な要素となります。信頼性の高い情報をプロンプトの前半に配置し、補足的な情報を後半に回すことで、より正確な応答を導き出せます。
| プロンプト構成要素 | 推奨される配置位置 |
|---|---|
| 主要な検索結果 | プロンプト前半 |
| 補足情報 | プロンプト後半 |
| 指示文 | 最終部分 |
コンテキストウィンドウの制限に対しては、検索結果の要約技術が効果的です。重要なキーワードや文脈を保持しながら、簡潔な形に情報を圧縮することで、限られたトークン数で最大限の情報を活用できます。
RAGを導入するメリット5選!業務効率化と顧客満足度向上を実現
RAGの導入は、企業の業務効率化と顧客満足度向上に大きな変革をもたらします。社内ナレッジの効率的な活用から、顧客対応品質の向上、データに基づく意思決定の実現まで、幅広い業務改善効果が期待できます。
さらに、業務プロセスの自動化による生産性向上や、セキュリティとコンプライアンスの強化など、現代のビジネス課題を解決する重要なソリューションとして注目されています。
1. 社内ナレッジを効率的に活用できる
社内に蓄積された膨大な情報資産を、RAGを活用することで効率的に検索・活用できるようになります。従来の検索システムと比較して、より文脈を理解した的確な情報抽出が可能になるため、業務効率の大幅な向上が期待できます。
RAGの特徴的な機能として、以下のような活用方法が挙げられます:
- 社内文書やマニュアルから必要な情報を即座に抽出し、回答を生成
- 部門横断的な知識共有を促進し、情報のサイロ化を防止
- 過去の対応事例や成功事例を学習し、類似案件への対応を効率化
- 新入社員の教育や業務引継ぎに活用し、学習曲線を短縮
特に重要なのは、RAGがセキュリティ面での課題も解決できる点です。アクセス権限の設定により、機密情報の取り扱いも安全に行えます。
また、データの更新や追加も容易なため、常に最新の情報を反映した回答が得られます。これにより、情報の陳腐化を防ぎ、より質の高い意思決定をサポートすることが可能となります。
2. 顧客対応の品質と速度が向上する
RAGを活用したカスタマーサポートでは、AIが社内のナレッジベースやFAQ、過去の対応履歴をリアルタイムで参照し、正確な情報に基づいた回答を提供できます。従来の検索システムと異なり、文脈を理解した上で最適な情報を抽出するため、一貫性のある質の高い対応が実現します。
顧客からの問い合わせに対する具体的な改善効果は以下の通りです:
- 回答時間の短縮:従来の手動検索と比べ、適切な情報の特定が最大70%迅速化
- 対応品質の向上:関連文書の自動参照により、回答の正確性が95%以上に向上
- 担当者の負荷軽減:複雑な質問への対応時間が平均40%削減
- 顧客満足度の改善:一次回答での解決率が30%以上上昇
特に技術的な質問や複雑な問い合わせに対しても、RAGは文脈を考慮しながら適切な情報を提示できます。これにより、カスタマーサポート担当者は迅速かつ的確な対応が可能となり、顧客満足度の向上につながります。
また、新人担当者でも豊富な対応ナレッジを活用できるため、経験による対応品質の差が少なくなるメリットもあります。
3. データに基づく意思決定が可能になる
RAGは、信頼性の高いデータベースを基盤とすることで、より確実な意思決定をサポートします。従来のAIシステムでは、データの信頼性や最新性に課題がありましたが、RAGでは常に検証されたデータソースを参照するため、より正確な判断が可能になります。
企業の意思決定において、最新の市場動向や業界トレンドを把握することは非常に重要です。RAGは、データベースを定期的に更新することで、常に最新の情報に基づいた判断を支援します。
| 意思決定の特徴 | 主なメリット |
|---|---|
| データの信頼性 | 検証済みソースからの情報提供 |
| 最新性の確保 | リアルタイムな情報更新 |
| 透明性 | 情報源の明確な提示 |
特に重要なのは、RAGを活用することで意思決定プロセスの透明性が向上する点です。すべての判断に対して、どのようなデータや情報源に基づいているかを明確に示すことができ、説明責任を果たすことができます。
4. 業務の自動化で生産性が高まる
RAGによる業務の自動化は、企業の生産性向上に大きな効果をもたらします。特に定型的な業務プロセスの自動化において、従業員の作業時間を大幅に削減できることが実証されています。
McKinseyの調査によると、RAGを活用した業務自動化により、データ入力や文書作成などの定型作業において平均50〜70%の時間削減が達成されています。これにより、従業員はより創造的な業務や戦略的な判断が必要な仕事に注力できるようになります。
| 業務タイプ | 時間削減効果 |
|---|---|
| データ入力作業 | 約65%削減 |
| 文書作成・要約 | 約55%削減 |
| 情報検索・整理 | 約70%削減 |
また、RAGシステムは24時間365日稼働が可能なため、時間外対応や休日対応も自動化できます。これにより、業務の連続性が保たれ、顧客満足度の向上にもつながっています。特に、グローバルビジネスにおける時差対応や、緊急性の高い問い合わせへの即時対応などで効果を発揮します。
5. セキュリティとコンプライアンスが強化される
RAGシステムには、企業の重要な情報資産を守るための高度なセキュリティ機能が実装されています。従来のAIシステムと比較して、データアクセスの制御や監査証跡の管理が格段に強化されているのが特徴です。
RAGを活用することで、以下のようなセキュリティ・コンプライアンス面での利点が得られます:
- アクセス権限の粒度の細かい制御により、ユーザーや部門ごとに参照できる情報を厳密に管理可能
- すべての検索クエリや生成された回答内容が自動的にログとして記録され、不正利用の検知や監査に活用可能
- データソースの追跡性が確保され、情報の出所や更新履歴を明確に把握可能
- 各種法規制やガイドラインに準拠した情報管理体制の構築をサポート
特に金融機関や医療機関など、厳格な情報管理が求められる業界では、RAGの導入によってコンプライアンス要件への対応が容易になります。また、システム管理者は定期的な監査を通じて、情報セキュリティの状態を常時把握することができます。
RAGの実践的な活用法と導入のステップ
RAGを実際のビジネスで活用するための具体的な手順と実践方法をご紹介します。システム構築の技術的な実装から、既存システムとの連携方法、実績のある活用事例まで、導入に必要な知識を体系的に解説していきます。
さらに、システムの評価・改善方法や、プロジェクトを確実に成功させるためのポイントもお伝えしていきましょう。
質問応答システムの具体的な構築方法
RAGベースの質問応答システムを構築するには、主要なライブラリと実装手順の理解が重要です。基本的な構築手順は以下の通りです。
必要なライブラリと環境設定
| ライブラリ | 主な用途 |
|---|---|
| LangChain | LLMとの連携、検索処理の実装 |
| Chromadb | ベクトルデータベースの構築 |
| OpenAI API | テキスト生成、埋め込み処理 |
まず、pip installコマンドで必要なライブラリをインストールします。その後、APIキーの設定と環境変数の構成を行います。
データの前処理では、テキストの分割やクリーニング、メタデータの付与を実施します。続いて、文書をベクトル化してChromadbに格納し、効率的な検索を可能にします。
回答生成時は、ユーザーの質問に関連する文書を検索し、それらをコンテキストとしてLLMに提供します。エラー処理やログ機能の実装も忘れずに行いましょう。
パフォーマンス向上には、チャンクサイズの最適化や類似度スコアのしきい値調整が効果的です。
既存の業務システムとの効果的な連携手順
既存の業務システムとRAGを連携させる際は、まず適切なデータ変換とインターフェースの設計が重要になります。
データ変換とAPI設計
既存システムのデータをRAGで利用可能な形式に変換するため、以下の手順で進めることをお勧めします。
- データベースやCRMからの情報抽出と標準フォーマットへの変換
- RESTful APIやGraphQL等による統一的なインターフェースの構築
- メタデータの付与によるデータの構造化と検索効率の向上
- 定期的な同期処理によるデータの鮮度維持
セキュリティと認証
システム間の連携においては、セキュリティの確保が不可欠です。OAuth2.0やJWTによる認証機構の実装、アクセス権限の細かな制御、通信の暗号化などを通じて、安全なデータ連携を実現します。
社内システムとRAGの統合には、段階的なアプローチを採用し、小規模な実証実験からスタートすることで、リスクを最小限に抑えながら効果的な連携を実現できます。
成功企業に学ぶRAGの活用事例
RAGの導入により、多くの企業が業務効率の大幅な改善を実現しています。代表的な成功事例をご紹介します。
| 企業名 | 導入分野 | 成果 |
|---|---|---|
| Microsoft | 社内文書管理 | 情報検索時間75%削減 |
| JPモルガン | 投資分析 | アナリスト生産性2倍 |
| Spotify | 顧客サポート | 対応時間60%短縮 |
Microsoftは、膨大な社内文書をRAGで統合管理することで、従業員の情報アクセス効率を劇的に向上させました。(出典:Microsoft Tech Community Blog)
JPモルガンでは、市場データと社内レポートをRAGで分析することで、アナリストの意思決定スピードが向上。投資判断の質も維持したまま、生産性を倍増させることに成功しています。(出典:JP Morgan Annual Report 2023)
Spotifyは顧客サポートにRAGを導入し、過去の対応履歴を活用した的確な回答により、問い合わせ対応の効率化と顧客満足度の向上を同時に達成しました。(出典:Spotify Engineering Blog)
システムの評価指標と改善サイクル
RAGシステムの性能を適切に評価し、継続的に改善していくためには、明確な評価指標の設定が不可欠です。以下が主要な評価指標とその測定方法になります。
| 評価項目 | 測定指標 | 目標値の目安 |
|---|---|---|
| 応答速度 | 平均応答時間 | 3秒以内 |
| 検索精度 | 適合率・再現率 | 80%以上 |
| 生成品質 | 人手評価スコア | 4.0/5.0以上 |
これらの指標を定期的に測定し、結果を分析することで改善が必要な領域を特定できます。特に検索精度の向上には、データの前処理やチャンク分割の最適化が効果的です。
システムの改善は、問題の特定→改善策の立案→実装→効果測定という PDCAサイクルで進めていきます。改善の優先順位は、ユーザーからのフィードバックと定量的な指標の両方を考慮して決定することが望ましいでしょう。
導入プロジェクトを成功に導くポイント
RAGシステムの導入を成功させるためには、プロジェクト開始前の綿密な計画と段階的な展開が不可欠です。特に重要となるのが、以下の3つの要素です。
- 明確なKPIと評価基準の設定:具体的な数値目標(レスポンス速度、検索精度など)を定め、達成度を客観的に測定できる指標を確立
- 技術要件の明確化:既存システムとの連携方法、必要なデータ形式、インフラ要件などを詳細に洗い出し
- 段階的な実装:パイロット環境での検証から開始し、フィードバックを基に改善を重ねながら本番環境へ移行
導入にあたっては、プロジェクトチーム内での役割分担を明確にし、定期的な進捗確認の場を設けることも大切です。
また、エンドユーザーとなる部門の意見を積極的に取り入れ、実際の業務フローに即したシステム設計を心がけましょう。
さらに、導入後の運用体制や保守計画についても事前に検討し、継続的な改善サイクルを確立することで、長期的な成功へとつながります。
まとめ
RAGは、AIチャットボットの性能を大幅に向上させる革新的な技術として注目を集めています。従来のAIと比べて正確性と信頼性が格段に高く、企業での実用化も進んでいます。
本記事では、RAGの基本的な仕組みから実践的な活用事例まで、幅広い観点から解説しました。RAGの導入を検討している方々の参考になれば幸いです。
この記事は役に立ちましたか?
感想は、今後の記事改善に活用します。
関連記事




次のAIツール選びへ
気になるツールを並べて、料金や特徴の違いを確認できます。